

In the enchanting realm of the world wide web, where millions of websites spin their intricate tales, it’s easy to overlook the guardians that protect their arcane treasures. These silent sentinels, known as robots.txt files, hold the power to unlock the secrets of web crawling, enabling search engines to explore the vast digital landscape. Yet, shrouded in mystery, robots.txt files often leave curious minds yearning for enlightenment. In this article, we embark on a captivating journey to demystify the enigmatic realm of robots.txt, shedding light on its purpose, functioning, and how it transforms the web crawling landscape. So, grab your metaphorical magnifying glass and prepare to uncover the hidden wonders behind the locked gates of robots.txt!
Table of Contents
- Understanding the Robots.txt File: A Key to Navigating the Web Crawling Landscape
- Unveiling the Mysteries: Decoding the Syntax and Directives of Robots.txt
- Optimizing Web Crawling: Best Practices for Robots.txt Implementation
- Robots.txt Dissection: Common Pitfalls and Recommendations
- Q&A
- To Conclude

Understanding the Robots.txt File: A Key to Navigating the Web Crawling Landscape
The Robots.txt file may seem like a mysterious entity, concealed within the depths of the web crawling realm. But fear not, for we are here to unravel the secrets and demystify its purpose. So, what exactly is a Robots.txt file? In simple terms, it is a text file that website administrators can create to instruct web robots or search engine crawlers on how to behave when they visit their site.
Now, you might be thinking, why is this file so important? Well, think of it as a traffic director for search engine crawlers. It guides these virtual robots, informing them which parts of a website are off-limits and which are open for exploration. Let’s break it down further into a couple of key points:
1. **Control access**: With a Robots.txt file, you have the power to control where the search engines can go on your website. It allows you to specify which pages or directories should not be crawled, ensuring that sensitive or irrelevant content remains hidden from search engine results.
2. **Directives**: The Robots.txt file uses directives to communicate instructions. These directives can be either “allow” or “disallow” commands instructing the crawlers to access or avoid certain areas of your website. You can even use wildcards to match different patterns or place restrictions on specific types of crawling activities. For instance, you can prevent search engines from indexing your images folder by including the “disallow: /images/” directive.
Understanding the Robots.txt file is like holding the master key to controlling search engine crawlers. By utilizing this file, you can safeguard your website’s privacy, protect sensitive data, and improve its overall visibility. So, let’s dive in deeper and uncover more intricate details about this fascinating glimpse into the world of web crawling.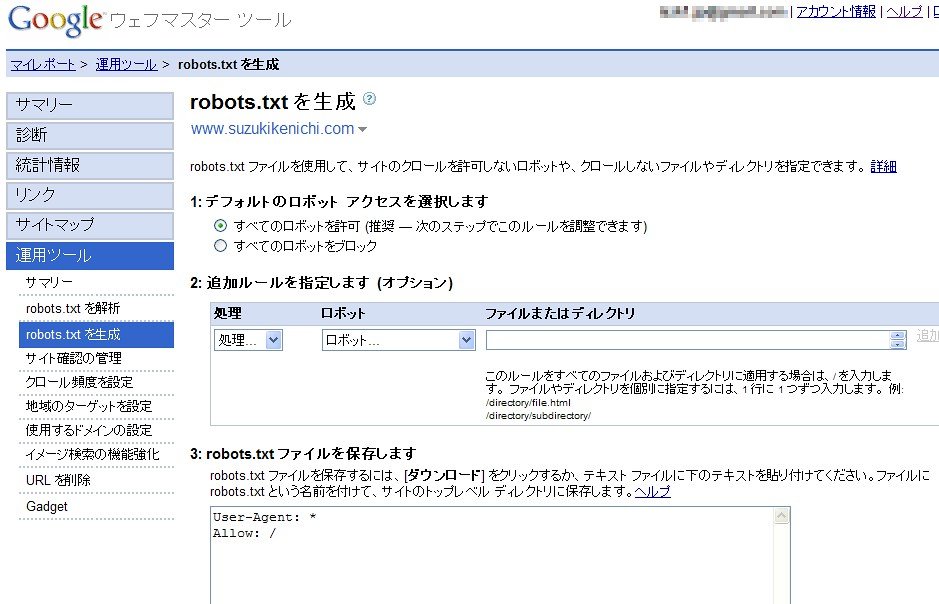
Unveiling the Mysteries: Decoding the Syntax and Directives of Robots.txt
Often overlooked and misunderstood, the enigmatic robots.txt file holds immense power in the realm of web crawling. Imagine it as the keeper of secrets, the gatekeeper to a website’s innermost chambers. In the web crawling world, this file acts as a guidebook, instructing search engine robots on what they can and cannot explore. So let’s embark on a journey, unwrapping the mysteries of robots.txt and discovering how its syntax and directives impact the way our websites are crawled and indexed.
Within the cryptic lines of a robots.txt file lies a set of rules that play a crucial role in shaping how search engines interact with our beloved websites. Syntax, or the structure of these rules, determines the format and organization of the directives. From simple *User-agent* declarations to precise *Disallow* instructions, each line carries meaning and purpose. Understanding how to structure these rules can grant us control over what search engines can access and index. It’s like a language all its own, and once you grasp its syntax, you hold the key to unlocking the full potential of your website’s visibility. So, let’s explore the syntax, decipher its components, and marvel at how a few characters can wield such immense power.
Optimizing Web Crawling: Best Practices for Robots.txt Implementation
When it comes to optimizing web crawling, implementing a robots.txt file is an essential practice that can unlock the secrets of efficient indexing for search engines. By demystifying the functionality of robots.txt, beginners can gain insightful knowledge on how to control the behavior of web crawlers effectively.
Understanding the Basics: Robots.txt is a simple text file that resides in the root directory of a website. It serves as a communication tool between your website and search engine crawlers, instructing them on which pages to crawl and which to exclude. By utilizing this file, you have the power to control the visibility and accessibility of your website’s content to search engines.
- Allow vs. Disallow: The robots.txt file allows you to specify whether you want search engine crawlers to access certain URLs or directories on your website. By using the “Allow” directive, you can permit crawling of specific pages or directories. Conversely, the “Disallow” directive informs crawlers to exclude certain areas from being indexed.
- User-agent Declarations: Different search engine crawlers, also known as user-agents, behave differently while crawling websites. In the robots.txt file, you can specify directives tailored to specific user-agents. This enables you to set different crawling rules for different search engines, ensuring optimal indexing for each platform.
- Wildcard Characters: Robots.txt supports the use of wildcard characters like “*” and “$”. The asterisk (*) acts as a placeholder for any sequence of characters, while the dollar sign ($) represents the end of the URL string. These wildcards come in handy when you want to apply a rule to multiple pages or directories with similar patterns.
By applying best practices for robots.txt implementation, you can fine-tune the behavior of web crawlers and maximize the visibility of your website in search engine results. Remember, robots.txt is a powerful tool that should be utilized strategically to control which content is indexed, ensuring an efficient crawl and better organic search performance.
Robots.txt Dissection: Common Pitfalls and Recommendations
Welcome to the fascinating world of robots.txt! In this section, we will unravel the mysteries surrounding this essential file in web crawling. Whether you are a beginner or just looking to deepen your understanding, let’s dive into common pitfalls and essential recommendations to make the most out of your robots.txt file. So, buckle up and get ready to unlock the secrets!
1. Pitfalls to Avoid:
- Overbroad Disallow Rules: One of the most common mistakes is setting a broad “Disallow” directive that unintentionally blocks crucial areas of your website. Double-check the syntax and make sure to specify only what you truly want to block.
- Leaving Out Important Directives: Neglecting to include essential directives, such as “User-agent” or “Sitemap,” can lead to unpredictable behavior from crawlers. Be thorough and include all necessary directives for proper communication.
- Conflicting Rules: It is crucial to avoid contradicting instructions within your robots.txt file. Crawlers follow a specific order when processing rules, so conflicting statements can cause confusion and potentially allow or block unintended areas of your website.
2. Recommendations for Effective Robots.txt:
- Know Your Crawler: Different crawlers have specific behaviors and support different directives. Familiarize yourself with the crawler you are targeting and use compatible directives to make the most out of your robots.txt file.
- Regular Updates: Websites evolve over time, and so should your robots.txt file. Make it a habit to review and update this file periodically to ensure it remains accurate and aligned with your website’s content and goals.
- Testing and Validation: Before deploying your robots.txt file, verify its correctness. Utilize online tools or validate it using the Webmasters’ verification tools provided by search engines to avoid unintended blocking or allowing crawlers to access sensitive areas.
By avoiding common pitfalls and implementing these recommendations, you can harness the true power of your robots.txt file. Remember, it’s a vital tool in guiding web crawlers, ensuring your website is crawled efficiently while protecting sensitive areas. So, start demystifying your robots.txt today and unlock new opportunities for seamless web crawling!
Q&A
Q: What is the purpose of a robots.txt file?
A: Ah, the mystical robots.txt! Its purpose is to control what content search engine crawlers can access on a website.
Q: Why is it called robots.txt?
A: Great question! The name “robots.txt” derives from its function to interact with web crawlers, often referred to as “robots”.
Q: How does robots.txt help in web crawling?
A: Robots.txt acts as a set of guidelines for web crawlers, instructing them which pages or directories they are allowed to crawl and index. It’s like leaving trail signs in a vast internet forest.
Q: Can robots.txt completely block a website from search engines?
A: Nope, it’s not that powerful. Think of robots.txt as a friendly request to search engines. While it does ask crawlers not to visit certain pages, they still have the freedom to explore if they choose to.
Q: Are there any limitations to what a robots.txt file can do?
A: Absolutely! Robots.txt cannot guarantee privacy or prevent access to sensitive information. It’s important to understand that it only serves as a suggestion to well-behaved web crawlers.
Q: Can I use robots.txt to hide embarrassing content?
A: Well, you can try, but remember, robots.txt is like a “No Entry” sign. While it discourages web crawlers from accessing specific pages, it’s not a foolproof way to conceal something you don’t want the world to see.
Q: Can robots.txt block unwanted web traffic?
A: Sadly, no. Robots.txt cannot stop humans from accessing your content. Its purpose lies solely in influencing the behavior of web crawlers, not filtering out unwanted human visitors.
Q: How do web crawlers interpret the rules in a robots.txt file?
A: Ah, the language of robots.txt! Web crawlers follow specific syntax laid out by the Robots Exclusion Standard. By adhering to these rules, crawlers understand which areas of your website are open for their exploration.
Q: Is robots.txt always necessary for a website?
A: Not necessarily. If you want search engines to freely crawl and index your entire website, you may not need a robots.txt file. However, it can be a helpful tool to manage access to certain pages or directories.
Q: Can robots.txt potentially harm a website’s visibility in search engines?
A: If misconfigured, robots.txt can indeed unintentionally block search engines from accessing important content. That’s why it’s crucial to ensure proper implementation and regularly review its rules.
Q: Are there any best practices for creating a robots.txt file?
A: Absolutely! Some best practices include regularly reviewing and updating your file, avoiding blocking too much or leaving your entire website unblocked, and testing its functionality with webmaster tools. Remember, balance is key!
Q: Can I use robots.txt to improve my website’s SEO?
A: While robots.txt can influence search engine crawling behavior, its direct impact on SEO is limited. Focusing on quality content, relevant keywords, and other optimization techniques will have a more significant impact on your website’s visibility.
Q: Anything else we should know about robots.txt?
A: Just remember that robots.txt is a powerful yet imperfect tool. It allows you to navigate the online realm with a bit more control, but it’s essential to grasp its limitations and use it wisely to unlock the secrets of web crawling. Happy crawling!
Closing Remarks
As we bring this passionate journey through the intricate world of robots.txt to a close, we hope to have unveiled the hidden truths that lie beneath its seemingly impenetrable surface. Our quest to demystify this enigmatic file has unraveled the secrets behind its creation, its purpose, and its influence on web crawling.
From the ancient codes of exclusion to the digital realms of the present, robots.txt has evolved into a sophisticated and multidimensional tool. It stands as the guardian that separates public access from hidden realms, protecting sensitive data while providing guidance to the ever-vigilant web crawlers.
But let us not forget that this text file, with its deceptively simple structure, holds within it the power to shape the very fabric of the internet. It cultivates a delicate dance between webmasters and search engine bots, enabling symbiotic relationships that lead to an organized and efficient digital ecosystem. By regulating the flow of information, robots.txt becomes the conductor of this virtual orchestra, ensuring harmony and preventing chaos.
Throughout our exploration, we have encountered the nuances and intricacies of robots.txt, uncovering its diverse uses beyond mere exclusions. From granting access to specific bots to defining crawl delays and sitemaps, this file emerges as a powerful tool for webmasters to exercise intimate control over their online presence.
But like any tool, robots.txt can be both a shield and a weapon. Its potential for misuse sparks debates surrounding transparency, privacy, and the ethics of web crawling. As we navigate this ever-evolving landscape, it becomes crucial for us as users, web developers, and information seekers to explore the grey areas and establish a balanced approach that respects the symbiotic relationship between humans and machines.
So, dear reader, we bid farewell, but not before leaving you with a deeper understanding of the cryptic world of robots.txt. Let this knowledge serve as your guide as you traverse the vast expanses of the internet, respecting the wishes of webmasters, and embracing the power of transparency.
May we continue to unravel the mysteries that lie ahead, marching boldly into the future where humans and robots coexist, intertwining their destinies, and forging a path towards a more harmonious digital existence.